Introduction
The world of data architecture has evolved dramatically over the past two decades. What started with traditional data warehouses has expanded into a complex ecosystem of storage and processing paradigms. In this comprehensive guide, I'll break down the three main architectures—Data Warehouses, Data Lakes, and Data Lakehouses—and explain how they work together in modern data platforms.
What is a Data Warehouse?
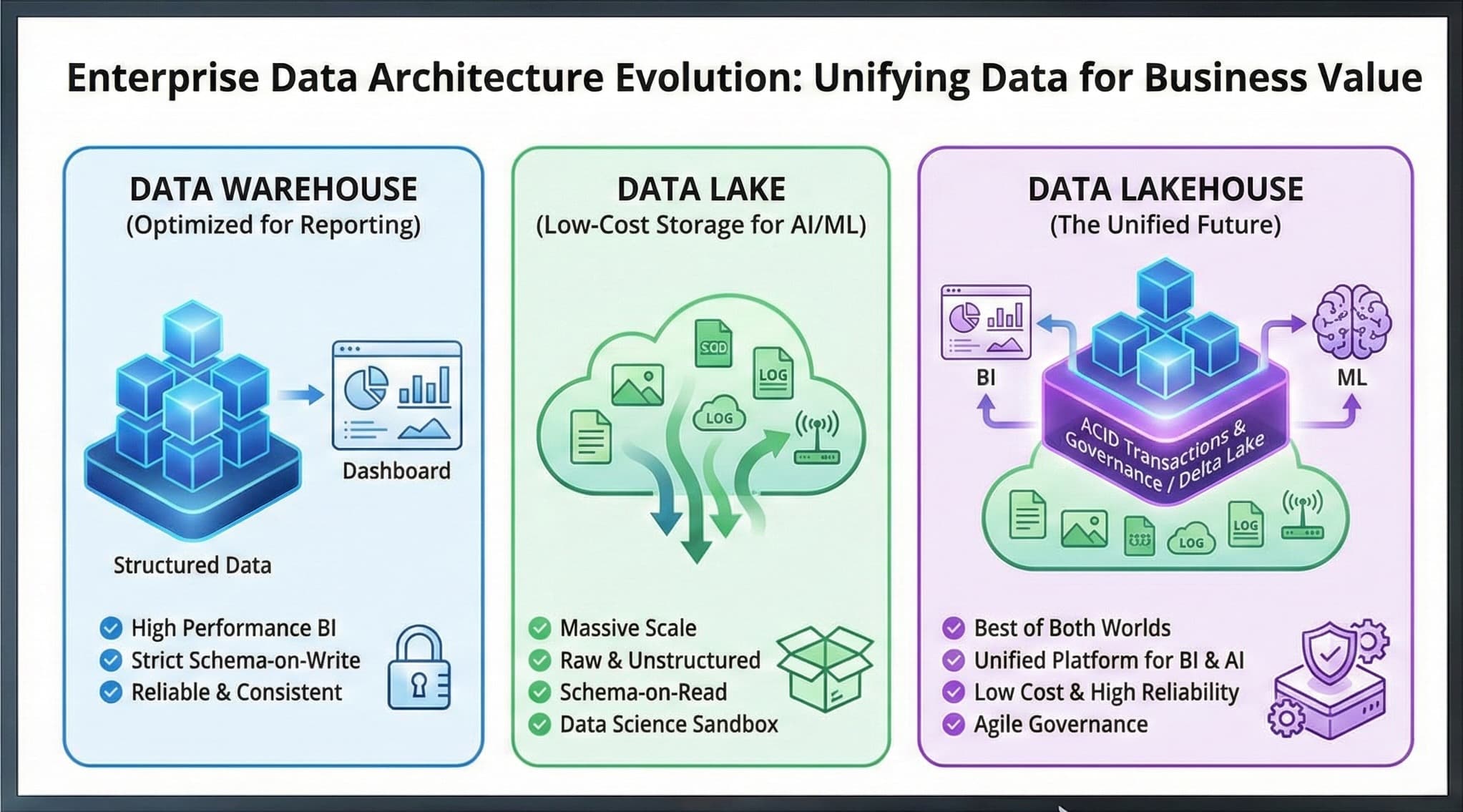
A **Data Warehouse** is a centralized repository designed specifically for analytics and business intelligence. Think of it as a highly organized library where every book (data) has been carefully cataloged and placed in exactly the right location.
Key Characteristics
**Structured Data**: Data warehouses store data in a predefined schema, typically using a star or snowflake schema design. Every table, column, and relationship is carefully defined before data enters the system.
**ACID Compliance**: They guarantee Atomicity, Consistency, Isolation, and Durability—essential for business-critical reporting where accuracy is paramount.
**Optimized for Reading**: Data warehouses use columnar storage and advanced indexing to make queries lightning-fast, even across billions of rows.
**ETL Processing**: Data goes through Extract, Transform, Load processes where it's cleaned, validated, and transformed before storage.
When to Use a Data Warehouse
Popular Technologies
What is a Data Lake?
A **Data Lake** is a massive storage repository that holds raw data in its native format. Unlike the organized library of a warehouse, a data lake is more like a vast ocean where data flows in from countless sources and stays in its original form.
Key Characteristics
**Schema-on-Read**: Unlike warehouses, data lakes don't require you to define structure upfront. You decide how to interpret the data when you read it, offering incredible flexibility.
**All Data Types**: Store structured databases, semi-structured JSON/XML, unstructured text, images, videos, sensor data, and log files—all in one place.
**Scalability**: Built on distributed storage systems like HDFS or cloud object storage (S3, Azure Blob), data lakes can scale to petabytes effortlessly.
**ELT Processing**: Extract, Load, Transform—data is stored first in raw form, then transformed as needed for specific use cases.
When to Use a Data Lake
Popular Technologies
The Data Lake Challenge
While data lakes offer flexibility, they can become "data swamps" if not properly governed. Without metadata management, data quality controls, and proper organization, finding and trusting data becomes difficult.
What is a Data Lakehouse?
The **Data Lakehouse** is the newest paradigm, emerging around 2020 to address the limitations of both warehouses and lakes. It combines the flexibility and scale of data lakes with the performance and reliability of data warehouses.
Key Characteristics
**Unified Storage**: One platform for all data types—structured, semi-structured, and unstructured—using open file formats like Parquet or Delta Lake.
**ACID Transactions on Data Lakes**: Technologies like Delta Lake, Apache Iceberg, and Apache Hudi bring database-like reliability to object storage.
**Schema Enforcement with Flexibility**: Support both schema-on-write (like warehouses) and schema-on-read (like lakes), giving you the best of both worlds.
**Direct Analytics**: Run SQL queries and machine learning directly on the lake without moving data to a separate warehouse.
**Time Travel & Versioning**: Track changes over time, roll back to previous versions, and audit data lineage.
When to Use a Data Lakehouse
Popular Technologies
The Data Mesh: A New Paradigm?
While lakehouse is the latest architecture pattern, there's another emerging concept worth mentioning: **Data Mesh**.
Unlike the previous three (which are technology architectures), Data Mesh is an **organizational and architectural paradigm** that treats data as a product owned by domain teams rather than a centralized platform.
Data Mesh Principles
1. **Domain-Oriented Ownership**: Each business domain owns and serves its data
2. **Data as a Product**: Treating data with product thinking—quality, discoverability, and user experience
3. **Self-Service Infrastructure**: Federated platform that enables domains to manage their own data
4. **Federated Computational Governance**: Automated, standardized governance policies
Data Mesh can be implemented **on top of** lakehouses, warehouses, or lakes—it's a different layer of thinking about how organizations structure their data teams and workflows.
How They Work Together
In modern enterprises, these architectures don't exist in isolation. Here's a typical integration pattern:
The Modern Data Platform
Ingestion Layer
Processing Layer
Consumption Layer
Governance Layer
Example Architecture
Sources → Data Lake (Raw) → Lakehouse (Curated) → Warehouse (Analytics)
↓
ML/AI Workloads
↓
Data Science Platform
Choosing the Right Architecture
Your choice depends on multiple factors:
Choose Data Warehouse When:
You have well-defined, structured data sources Business intelligence is your primary use case You need guaranteed performance SLAs for reports Regulatory compliance requires strict controls Choose Data Lake When:
You're collecting diverse, unstructured data Machine learning and data science are primary workloads Schema is unknown or frequently changing Cost-effective storage of massive volumes is critical Choose Data Lakehouse When:
You need both BI and ML capabilities You want to reduce infrastructure complexity You're building a modern cloud-native platform You want to eliminate data silos and duplication Real-World Implementation Tips
From my experience implementing these architectures across financial services, retail, and telecom:
Start Simple
Don't over-engineer. Many organizations succeed with a simple S3 + Athena setup before investing in complex lakehouse platforms.
Invest in Governance Early
Whether warehouse, lake, or lakehouse—metadata management, data quality, and access controls must be in place from day one.
Consider Total Cost
Warehouses charge by query compute; lakes charge by storage; lakehouses balance both. Model your actual usage patterns before committing.
Plan for Evolution
Today's warehouse may become tomorrow's lakehouse. Design with flexibility and avoid vendor lock-in where possible.
Conclusion
The evolution from data warehouses to lakes to lakehouses reflects the industry's journey toward more flexible, scalable, and unified data platforms.
**Data warehouses** remain the gold standard for business intelligence with structured data. **Data lakes** excel at storing massive volumes of diverse data cost-effectively. **Data lakehouses** combine both capabilities, representing the future of cloud data platforms.
And with **Data Mesh** entering the conversation, we're not just thinking about technology architecture but organizational structure around data ownership and products.
The best architecture for your organization depends on your specific use cases, data types, team capabilities, and business requirements. Often, the answer is a combination of these approaches working together in a modern data platform.
**Ready to architect your data platform?** Let's discuss your specific requirements and design a solution that fits your needs. [Connect with me on LinkedIn](https://www.linkedin.com/in/gpolar) or check out my [data architecture resources](/resources).